Abstract
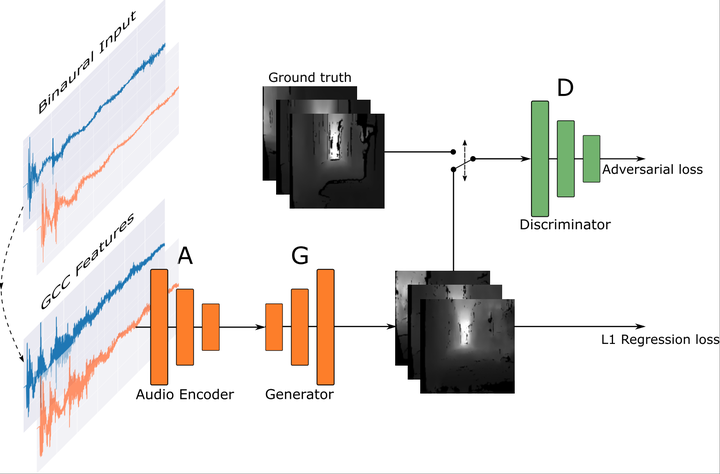
Inspired by sophisticated echolocation abilities found in nature, we train a generative adversarial network to predict plausible depth maps and grayscale layouts from sound. To achieve this, our sound-to-vision model processes binaural echo-returns from chirping sounds. We build upon previous work with BatVision that consists of a sound-to-vision model and a self-collected dataset using our mobile robot and low-cost hardware. We improve on the previous model by introducing several changes to the model, which leads to a better depth and grayscale estimation, and increased perceptual quality. Rather than using raw binaural waveforms as input, we generate generalized cross-correlation (GCC) features and use these as input instead. In addition, we change the model generator and base it on residual learning and use spectral normalization in the discriminator. We compare and present both quantitative and qualitative improvements over our previous BatVision model.